the art and science of learning from data
data aotearoa 2024
2024-03-08
scan for slides

or go to link.lizabolton.com
quick, write! what’s your experience with “statistics”?
Go to this link1 and write a short answer. It is anonymous.

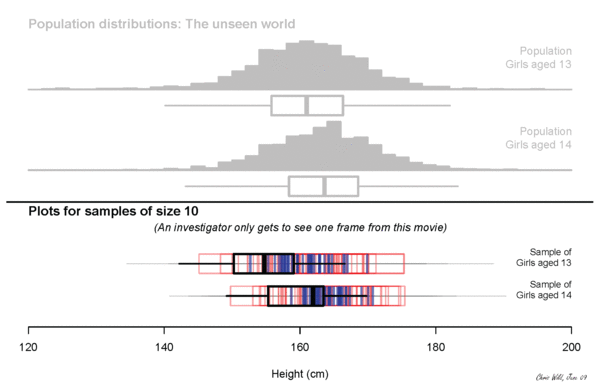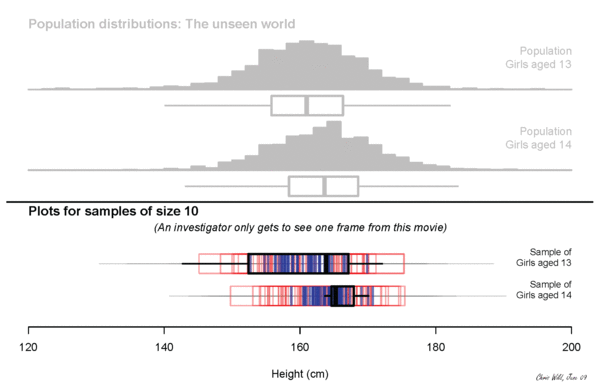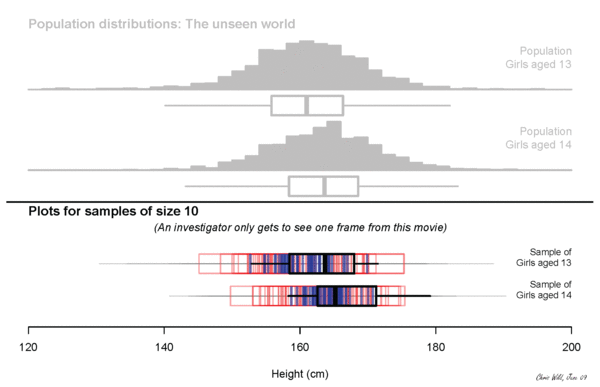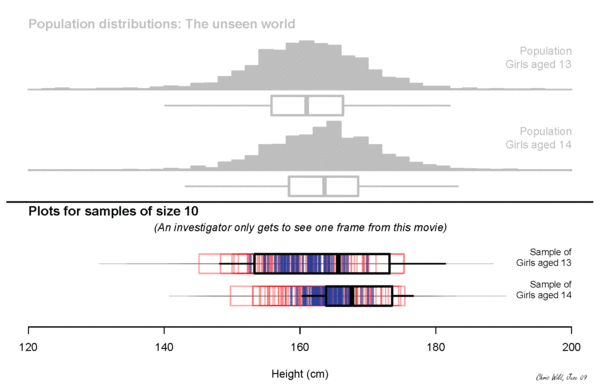
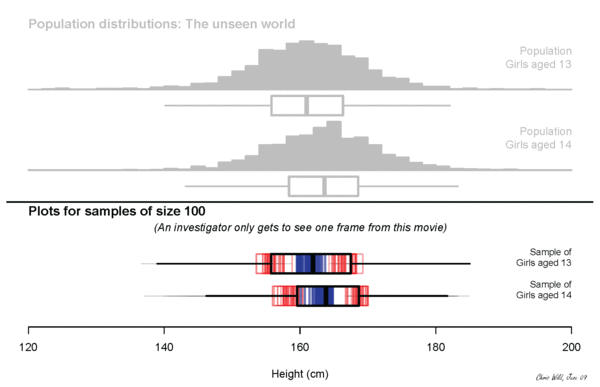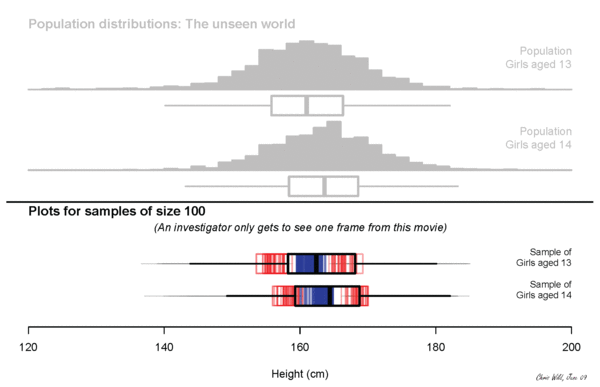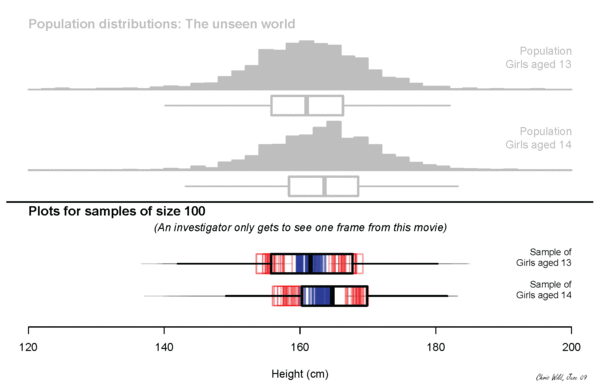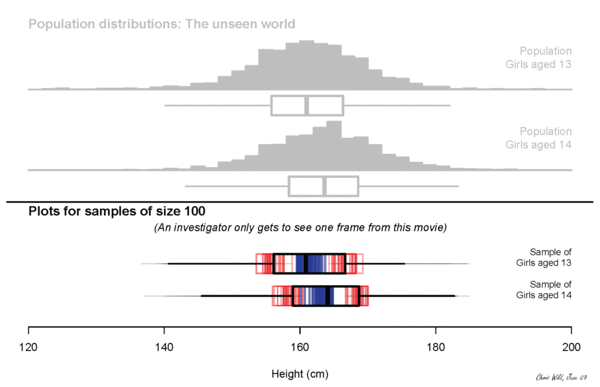
what will we measure?
Height? Income?

plot some simulated data
Show the code
# To simulate the same way each time
set.seed(8)
# Simulate some data
data <- tibble(scenario = rep(c("No var", "Low var", "High var"), each = 100), value = c(rep(0, 100), rnorm(100), rnorm(100, sd = 5)))
# Liza's colours
colors <- c("#3C143F", "#87528A", "#808080")
# Plot!
ggplot(data, aes(x = value, group = scenario,
fill = scenario, color = scenario)) +
geom_dotplot(bins = 20) +
scale_fill_manual(values = colors) + # Set manual color codes
scale_color_manual(values = colors) +
theme_minimal() +
facet_wrap(~scenario)
bogs

seeing what is not there
This might sounds strange coming from a statistician, but sometimes the most important data story is the story about where the data isn’t. What’s MISSING?
🖼️ Check out the incredible mixed-media installation The Library of Missing Datasets (2016) by MIMI ỌNỤỌHA. It is “a physical repository of those things that have been excluded in a society where so much is collected.
“Missing data sets” are the blank spots that exist in spaces that are otherwise data-saturated.”


In October 1995 the UK Committee on Safety of Medicines announced people taking 3rd generation oral contraceptive (OC) pills had double the risk of blood clots of 2nd generation OCs.
That is a 100% increase

 {fig-alt=“Clippings from the Guardian newspaper with title”Blood clot alert on the pill: Women warned about 7 brands of contraceptive”. The text goes on to say: “One and a half million women were told yesterday that their brand of contraceptive pill could double the risk of a blood clot, provoking the biggest scare over the safety of oral contracepetives.”}
{fig-alt=“Clippings from the Guardian newspaper with title”Blood clot alert on the pill: Women warned about 7 brands of contraceptive”. The text goes on to say: “One and a half million women were told yesterday that their brand of contraceptive pill could double the risk of a blood clot, provoking the biggest scare over the safety of oral contracepetives.”}
 {fig-alt=“Clipping from the Guardian newspaper with title”Hundreds of callers inundate clinic for advice on warning”}
{fig-alt=“Clipping from the Guardian newspaper with title”Hundreds of callers inundate clinic for advice on warning”}
quick, write!
what follow-up question(s) do you have about this headline/info?
Go to this link and write a short answer. It is anonymous.
Oral contraceptives were already known to increase risk of blood clots.

“For the vast majority of women, the pill is a safe and highly effective form of contraception. …
No-one need stop taking the pill before obtaining medical advice.”
~ Advice from UK Committee on Safety of Medicines in the same message



13,500 more abortions

an estimated 800 additional conceptions among girls under 16

£4 - 6 million spent on abortions by the National Health Service (NHS)




run, run as fast as you can

The regression lines are extrapolated (broken blue and red lines for men and women, respectively) and 95% confidence intervals (dotted black lines) based on the available points are superimposed. The projections intersect just before the 2156 Olympics, when the winning women’s 100-metre sprint time of 8.079 s will be faster than the men’s at 8.098 s. From: Momentous sprint at the 2156 Olympics?
quick, write!
what does this chart tell you? any concerns?
Go to this link and write a short answer. It is anonymous.
for whom the (cow)bell tolls


This graph is from an article entitled Music to die for: how genre affects popular musicians’ life expectancy, the Conversations
quick, write!
what does this chart tell you? any concerns?
Go to this link and write a short answer. It is anonymous.